Linux Bridges¶
Table of Contents
Iniciando con Linux Bridges¶
Un virtual network switch o bridge es equivalente a un switch físico con la diferencia de que un Linux bridge posee un número ilimitado de puertos virtuales. Podemos conectar VMs a estos puertos virtuales. Del mismo modo que un switch físico, el bridge aprende direcciones MAC de paquetes recibidos y los guarda en una MAC table, la cual usa para tomar decisiones de forwarding de tramas.
Instalando herramientas y cargando módulos¶
- Para administrar bridges necesitamos una herramienta llamada
brctlque se obtiene instalando el paquetebridge-utils. Para instalarlo ejecutaremos:
- Con
apt:sudo apt-get install -y bridge-utils - Con
yum:sudo yum install -y bridge-utils
- Luego debemos asegurarnos que el módulo de bridge esté cargado:
$ lsmod | grep bridge
bridge 155648 0
Si el módulo no estuviese cargado usar modprobe bridge para cargarlo al kernel.
Creando un Linux Bridge¶
- Para crear un bridge llamado
brtestusamos el comandobrctl:
$ sudo brctl addbr brtest
- Para listar los bridges disponibles con información como el ID del bridge, estado del Spanning Tree Protocol (STP), y las interfaces conectadas al bridge, ejecutamos:
$ brctl show
bridge name bridge id STP enabled interfaces
brtest 8000.000000000000 no
- Un Linux bridge también se mostrará como un dispositivo de red. Para ver los detalles de red del bridge creado usaremos el comando
ipoifconfig:
$ ip link show brtest
18: brtest: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 66:43:4a:a2:9f:3e brd ff:ff:ff:ff:ff:ff
$ ifconfig brtest
brtest: flags=4098<BROADCAST,MULTICAST> mtu 1500
ether 66:43:4a:a2:9f:3e txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
El Linux bridge está listo. Ahora creamos y conectaremos un dispositivo TAP a él.
Linux Bridges con Interfaces TAP¶
Teoría de dispositivos TAP¶
Podemos conectar a los puertos del bridge dispositivos de red espaciales llamados TAP devices. El equivalente de networking físico de un dispositivo TAP sería un cable de red encargado de portar los frames de Ethernet entre la VM y el bridge. Los dispositivos TAP forman parte de una tecnología mayor conocida como la implementación TUN/TAP.
Important
- TUN, que representa “tunnel”, simula a dispositivo de capa de red y trabaja con paquetes de la capa 3 del modelo de referencia OSI, como los paquetes IP. TUN es usado con enrutamiento.
- TAP (a saber, un network tap) simula un dispositivo de capa de enlace y opera con paquetes de la capa 2 del modelo de referencia OSI, como los Ethernet frames (tramas). TAP es usado para crear un network bridge.
Cargando módulos TUN/TAP¶
Igual que se verificó con Linux Bridges, verificar que el módulo TUN/TAP esté cargando en el kernel:
$ lsmod | grep tap
Module Size Used by
tap 24576 1 vhost_net
Si no estuviese cargado alguno de los módulos usar modprobe tun y/o modprobe tap para cargarlo al kernel.
Creando un dispositivo TAP¶
Crear un dispositivo TAP llamado tap-vnic con el comando ip:
$ sudo ip tuntap add dev tap-vnic mode tap
Veamos la interfaz TAP creada con el comando ip:
$ ip link show tap-vnic
19: tap-vnic: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 76:0e:4c:78:0d:be brd ff:ff:ff:ff:ff:ff
Conectando un dispositivo TAP al bridge¶
Hasta el momento tenemos creado un brdige llamado tap-vnic y un dispositivo TAP llamado tap-vnic. Ahora añadamos el TAP al bridge:
$ sudo brctl addif brtest tap-vnic
$ brctl show
bridge name bridge id STP enabled interfaces
brtest 8000.760e4c780dbe no tap-vnic
Ahora vemos a la interfaz tap-vnic añadida al bridge brtest. tap-vnic puede funcionar como la interfaz entre nuestra VM y el bridge brtest, que a su vez permite a la VM comunicarse con otras VMs añadidas a este bridge:

Conexión entre VMs con Linux bridge e interfaces TAP
Observaremos ciertos cambios luego de haber conectado la interfaz al bridge:
- La dirección MAC del bridge luego de añadir el dispositivo TAP ha cambiado:
$ ip link show brtest
18: brtest: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 76:0e:4c:78:0d:be brd ff:ff:ff:ff:ff:ff
- Es posible ver la tabla MAC del bridge
brtestcon el comandobrctl showmacs brtest:
$ brctl showmacs brtest
port no mac addr is local? ageing timer
1 76:0e:4c:78:0d:be yes 0.00
1 76:0e:4c:78:0d:be yes 0.00
- Además podemos agregar una dirección IP al bridge:
$ sudo ip addr add 192.168.99.1/24 dev brtest
$ ip addr show brtest
18: brtest: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 76:0e:4c:78:0d:be brd ff:ff:ff:ff:ff:ff
inet 192.168.99.1/24 scope global brtest
valid_lft forever preferred_lft forever
Deshacer configuración de Linux Bridge con interfaces TAP¶
- Primero desconectaremos el dispositivo TAP del bridge:
$ sudo brctl delif brtest tap-vnic
$ brctl show brtest
bridge name bridge id STP enabled interfaces
brtest 8000.000000000000 no
- Luego eliminaremos el dispositivo TAP usando el comando
ip:
$ sudo ip tuntap del dev tap-vnic mode tap
- Finalmente eliminamos el bridge:
$ sudo brctl delbr brtest
Todos estos pasos que hemos realizado son los mismos que libvirt lleva acabo en el backend mientras habilita o deshabilita networking para una VM.
Configuración adicional del Linux Bridge¶
- Asignar una dirección MAC a la interfaz de red del bridge con el comando
ip link:
$ sudo ip link set brtest address 02:01:02:03:04:05
$ ip link show brtest
16: brtest: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 02:01:02:03:04:04 brd ff:ff:ff:ff:ff:ff
- Activar STP en el Linux Bridge (sin STP no existe Ping entre PCs conectadas a través de un Linux Bridge con veth pairs):
$ sudo brctl stp brtest on
Note
Para ver todas las opciones disponibles de brctl usar: brctl --help
$ brctl --help
Usage: brctl [commands]
commands:
addbr <bridge> add bridge
delbr <bridge> delete bridge
addif <bridge> <device> add interface to bridge
delif <bridge> <device> delete interface from bridge
hairpin <bridge> <port> {on|off} turn hairpin on/off
setageing <bridge> <time> set ageing time
setbridgeprio <bridge> <prio> set bridge priority
setfd <bridge> <time> set bridge forward delay
sethello <bridge> <time> set hello time
setmaxage <bridge> <time> set max message age
setpathcost <bridge> <port> <cost> set path cost
setportprio <bridge> <port> <prio> set port priority
show [ <bridge> ] show a list of bridges
showmacs <bridge> show a list of mac addrs
showstp <bridge> show bridge stp info
stp <bridge> {on|off} turn stp on/off
Linux Bridges con Network Namespaces e Interfaces veth¶
Namespaces¶
Teoría de Network Namespaces¶
Una instalación de Linux comparte un único conjunto de interfaces de red y entradas de tablas de enrutamiento. Con network namespaces podemos tener instancias diferentes y separadas de las interfaces de red y tablas de enrutamiento que operan independientemente una de otra. (Referencia: Introducing Linux Network Namespaces)
Creando y listando network namespaces¶
- Para crear un network namespace usamos el comando
ip netns:
$ sudo ip netns add mynetns
- Para listar los network namespaces creados usamos:
$ ip netns show
mynetns
Luego de haber creado un network namespace el siguiente paso será asignar interfaces (virtuales o físicas) al namespace para luego configurarlas y lograr conectividad de red.
Interfaces veth¶
Asignando interfaces veth a network namespaces¶
Una opción para asignar interfaces a network namespaces son las interfaces virtuales también conocidas como interfaces virtual Ethernet (veth) a un network namespace.
Las interfaces veth están construidas en pares, de forma que lo que entre por una interfaz veth salga por su otra interfaz veth par (peer). De esta forma podemos usar las interfaces veth para conectar un network namespace con el mundo exterior.
Para crear un veth pair usamos el comando ip:
$ sudo ip link add vethA type veth peer name vethB
Otra opción equivalente es agregando dev al comando: sudo ip link add dev veth1 type veth peer name veth2
Podemos ver el par de interfaces veth creado con el comando ip:
$ ip link
8: vethB@vethA: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 96:58:a7:73:a7:b1 brd ff:ff:ff:ff:ff:ff
9: vethA@vethB: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 1e:da:c1:92:7b:99 brd ff:ff:ff:ff:ff:ff
Como vemos, ambas interfaces pertenecen al namespace “default” o “global”, junto con las interfaces físicas.
Digamos que ahora queremos conectar el namespace global al namespace creado por nosotros (mynetns). Para hacerlo, movemos una de las interfaces veth a nuestro namespace mynetns con el comando ip:
$ sudo ip link set vethA netns mynetns
Si fuésemos a listar las interfaces físicas de nuestro sistema, veremos que la interfaz vethA ha desaparecido de la lista:
$ ip link
8: vethB@if9: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 96:58:a7:73:a7:b1 brd ff:ff:ff:ff:ff:ff link-netnsid 0
Ahora la interfaz vethA se encuentra en el namespace mynetns, como lo podemos comprobar con:
$ sudo ip netns exec mynetns ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
9: vethA@if8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 1e:da:c1:92:7b:99 brd ff:ff:ff:ff:ff:ff link-netnsid 0
Podemos dividir el comando en dos partes:
ip netns exec mynetns: ejecutar un comando en un network namespace diferente (mynetns)ip link show: comando a ejecutar en el network namespace
En general, podemos ejecutar cualquier comando para la configuración de red dentro del namespace (ip addr, ip route, ip link, ifconfig, ping) con el siguiente formato:
$ ip netns exec <netns> <comando a correr en el netns>
Conectando una interfaz veth al bridge¶
Para lograr la comunicación de dos network namespaces (o VMs) podemos conectar estos dispositivos a un bridge. Para esto, conectaremos cada network namespace (o VM) con un veth pair al bridge. Sigamos el siguiente esquema como ejemplo:
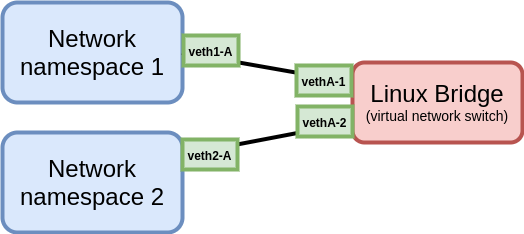
Conexión entre network namespaces con un Linux bridge e interfaces veth
- Primero crearemos los namespaces
PC1yPC2:
$ sudo ip netns add PC1
$ sudo ip netns add PC2
$ ip netns show
PC2
PC1
- Luego crearemos el bridge
SW-A:
$ sudo brctl addbr SW-A
$ brctl show
bridge name bridge id STP enabled interfaces
SW-A 8000.000000000000 no
- Posteriormente creamos dos veth pair:
$ sudo ip link add veth1-A type veth peer name vethA-1
$ sudo ip link add veth2-A type veth peer name vethA-2
- Asignamos una interfaz de cada veth pair a un network namespace:
$ sudo ip link set veth1-A netns PC1
$ sudo ip link set veth2-A netns PC2
- Asignamos el otro extremo de cada veth pair al único bridge creado:
$ sudo brctl addif SW-A vethA-1
$ sudo brctl addif SW-A vethA-2
$ brctl show
bridge name bridge id STP enabled interfaces
SW-A 8000.168a27b2ea41 no vethA-1
vethA-2
Como vemos, hemos conectado un extremo de cada veth pair al bridge SW-A.
- Asignar una dirección IP dentro del mismo rango de red a cada interfaz del veth pair conectada a cada namespace:
$ sudo ip netns exec PC1 ip addr add 192.168.99.1/24 dev veth1-A
$ sudo ip netns exec PC2 ip addr add 192.168.99.2/24 dev veth2-A
- Prender las interfaces conectadas a los network namespace y al bridge:
# Interfaces conectadas a namespaces PC1 y PC2
$ sudo ip netns exec PC1 ip link set dev veth1-A up
$ sudo ip netns exec PC2 ip link set dev veth2-A up
# Interfaz propia del bridge
$ sudo ip link set dev SW-A up
# Interfaces conectadas al bridge
$ sudo ip link set dev vethA-1 up
$ sudo ip link set dev vethA-2 up
- Revisamos la configuración de las interfaces de los network namespace y el bridge:
# Configuración de red de network namespace PC1
$ sudo ip netns exec PC1 ip addr show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
12: veth1-A@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 7e:81:4e:49:c2:a8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.99.1/24 scope global veth1-A
valid_lft forever preferred_lft forever
inet6 fe80::7c81:4eff:fe49:c2a8/64 scope link
valid_lft forever preferred_lft forever
# Configuración de red de network namespace PC2
$ sudo ip netns exec PC2 ip addr show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
14: veth2-A@if13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 82:84:81:8a:a2:ac brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.99.2/24 scope global veth2-A
valid_lft forever preferred_lft forever
inet6 fe80::8084:81ff:fe8a:a2ac/64 scope link
valid_lft forever preferred_lft forever
# Configuración de red del bridge SW-A
$ ip link
10: SW-A: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 16:8a:27:b2:ea:41 brd ff:ff:ff:ff:ff:ff
11: vethA-1@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master SW-A state UP mode DEFAULT group default qlen 1000
link/ether a6:96:81:e7:bb:3b brd ff:ff:ff:ff:ff:ff link-netnsid 1
13: vethA-2@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master SW-A state UP mode DEFAULT group default qlen 1000
link/ether 16:8a:27:b2:ea:41 brd ff:ff:ff:ff:ff:ff link-netnsid 2
- Probar conectividad entre network namespaces
PC1yPC2:
$ sudo ip netns exec PC1 ping -c3 192.168.99.2
PING 192.168.99.2 (192.168.99.2) 56(84) bytes of data.
64 bytes from 192.168.99.2: icmp_seq=1 ttl=64 time=0.067 ms
64 bytes from 192.168.99.2: icmp_seq=2 ttl=64 time=0.078 ms
64 bytes from 192.168.99.2: icmp_seq=3 ttl=64 time=0.065 ms
--- 192.168.99.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2033ms
rtt min/avg/max/mdev = 0.065/0.070/0.078/0.005 ms
$ sudo ip netns exec PC2 ping -c3 192.168.99.1
PING 192.168.99.1 (192.168.99.1) 56(84) bytes of data.
64 bytes from 192.168.99.1: icmp_seq=1 ttl=64 time=0.057 ms
64 bytes from 192.168.99.1: icmp_seq=2 ttl=64 time=0.077 ms
64 bytes from 192.168.99.1: icmp_seq=3 ttl=64 time=0.108 ms
--- 192.168.99.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2029ms
rtt min/avg/max/mdev = 0.057/0.080/0.108/0.023 ms